요즘 AI 반도체에 투자하거나 GPU를 도입하려는 분이라면 가장 먼저 부딪히는 질문이 바로 엔비디아 AMD AI칩 비교입니다. “엔비디아가 압도적이라는데 AMD는 왜 사지?”, “성능은 누가 위고 가격은 누가 싼가?” 같은 궁금증이죠.
10년 넘게 반도체·테크 섹터를 들여다본 입장에서 말씀드리면, 2026년은 이 구도가 처음으로 흔들리기 시작한 해입니다. 그래서 단순 스펙표가 아니라 성능·소프트웨어·로드맵·투자까지 실전 관점으로 풀어보겠습니다.

목차
엔비디아 vs AMD AI칩, 핵심 차이 한눈에
먼저 큰 그림부터 잡겠습니다. 2026년 현재 시장에서 실제로 굴러가는 두 회사의 주력 칩은 엔비디아 B200(블랙웰)과 AMD MI355X(CDNA 4)입니다.
한 줄로 요약하면 이렇습니다.
엔비디아는 ‘소프트웨어와 생태계’, AMD는 ‘메모리와 가성비’로 싸운다.
이 한 문장이 엔비디아 AMD AI칩 비교의 전부라고 해도 과언이 아닙니다. 칩 자체의 순수 연산력은 이제 박빙입니다. 차이를 만드는 건 그 위에 쌓인 소프트웨어, 그리고 클러스터로 묶었을 때의 효율이죠.
먼저 두 주력 칩의 핵심 스펙을 표로 보겠습니다.
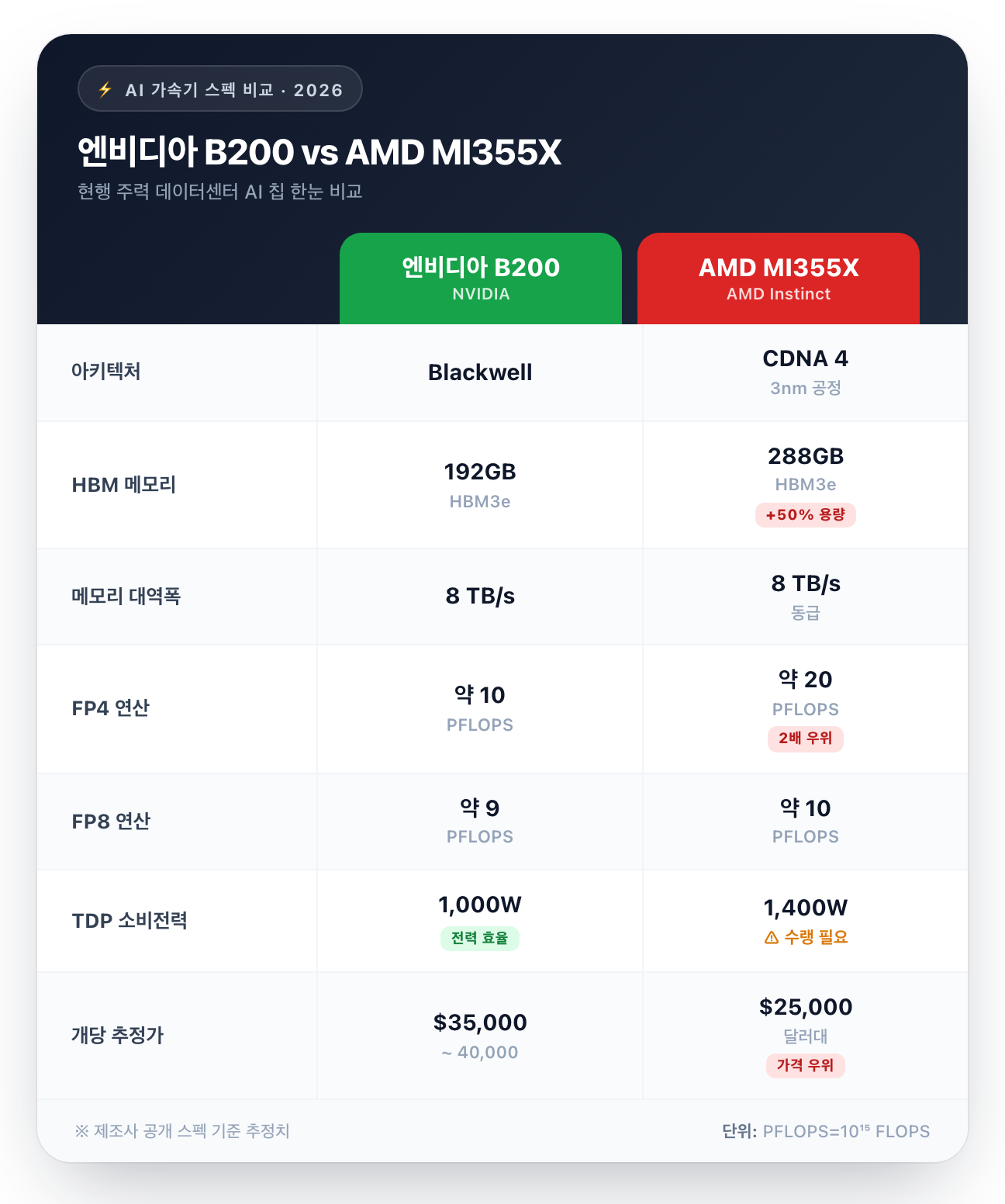
표에서 가장 눈에 띄는 건 메모리 용량입니다. MI355X는 288GB로 B200(192GB)보다 50% 큽니다.
왜 메모리가 중요할까요? LLM 추론에서는 모델 파라미터를 GPU 메모리에 통째로 올려야 하는데, 메모리가 크면 더 적은 칩으로 더 큰 모델을 돌릴 수 있습니다. 칩 수가 줄면 전력·네트워크 비용이 함께 줄죠.
반면 엔비디아는 칩 한 장의 절대 성능보다 수만 장을 묶었을 때의 효율에서 앞섭니다. NVLink, InfiniBand, 그리고 CUDA로 이어지는 풀스택이 그 비결입니다.
실전 팁
“칩 하나 스펙”만 보고 우열을 가리면 오판하기 쉽습니다. 실제 데이터센터는 GPU 수천~수만 장을 하나의 클러스터로 묶어 쓰기 때문에, ‘칩 단위 스펙’보다 ‘랙·클러스터 단위 효율’이 구매 결정을 좌우합니다.
성능 비교: 메모리·연산·전력의 진짜 차이
이제 숫자로 깊이 들어가 보겠습니다. 엔비디아 AMD AI 가속기 성능 차이는 크게 세 갈래로 나뉩니다. 메모리, 연산, 그리고 전력 효율입니다.
① 메모리: AMD의 가장 확실한 무기
MI355X는 288GB HBM3e를 탑재합니다. B200은 192GB입니다.
대역폭은 양쪽 다 8 TB/s로 동일합니다. 즉 ‘데이터를 얼마나 빨리 나르냐’는 비슷한데, ‘얼마나 담을 수 있냐’는 AMD가 앞섭니다.
이 차이는 405B(4,050억 파라미터)급 초대형 모델 추론에서 결정적입니다. 메모리가 크면 모델을 쪼개는 횟수가 줄어 지연시간(latency)이 짧아집니다.
실제 벤치마크에서도 드러납니다. Llama 3.1 405B 추론에서 MI355X가 B200보다 약 30% 빠른 것으로 나타났는데, 이는 엔비디아의 상위 구성인 GB200에 맞먹는 수준입니다.
② 연산력: 저정밀 포맷에서 AMD가 치고 나간다
요즘 AI 추론의 핵심은 FP4·FP6 같은 저정밀 연산입니다. 정밀도를 낮추는 대신 처리량을 폭발적으로 끌어올리는 방식이죠.
MI355X의 FP4 피크는 약 20 PFLOPS로, B200(약 10 PFLOPS)의 두 배 수준입니다. FP8에서도 MI355X가 약 10 PFLOPS로 B200(약 9 PFLOPS)을 근소하게 앞섭니다.
과학·공학 계산에 쓰이는 FP64(배정밀도)에서는 격차가 더 큽니다. MI355X는 약 79 TFLOPS로 B200(약 37~40 TFLOPS)의 두 배에 가깝습니다.
순수 연산 스펙만 보면 MI355X가 종이 위에선 더 화려하다.
다만 ‘종이 위’라는 단서를 강조하고 싶습니다. 스펙시트 피크 성능과 실제 워크로드 성능은 다릅니다. 그 간극을 메우는 게 다음 섹션의 소프트웨어죠.
③ 전력: 더 센 성능엔 더 큰 전기료
성능이 공짜는 아닙니다. MI355X의 TDP는 1,400W로, B200(1,000W)보다 40% 높습니다.
게다가 MI355X는 발열 때문에 수랭(액체냉각)이 사실상 필수입니다. 데이터센터 입장에서는 냉각 인프라 투자가 추가로 들어갑니다.
그래서 전력당 성능(perf/watt)을 따지면 격차가 좁혀집니다. AMD는 ‘칩당 처리량’에서, 엔비디아는 ‘전력·공간 효율’에서 점수를 가져가는 구도입니다.
이 섹션 핵심
메모리(288GB vs 192GB)와 저정밀 연산(FP4 20 vs 10 PFLOPS)은 AMD가 앞섭니다. 하지만 AMD는 전력을 40% 더 먹고 수랭이 필요합니다. 스펙시트 승자와 실사용 승자는 다를 수 있습니다.
진짜 승부처는 소프트웨어 — CUDA vs ROCm
여기서부터가 진짜입니다. 많은 분이 간과하지만, AI 가속기 시장에서 엔비디아가 80~90%를 장악한 이유는 칩이 아니라 CUDA입니다.
CUDA가 만든 10년의 해자
CUDA는 2007년부터 쌓인 소프트웨어 생태계입니다. 거의 모든 머신러닝 프레임워크, 최적화 라이브러리, 디버깅 도구가 ‘CUDA 우선’으로 설계돼 왔습니다.
개발자 입장에서 엔비디아 GPU는 ‘그냥 켜면 돌아가는’ 환경입니다. 이 편의성이 곧 전환비용이자 해자(moat)죠.
AMD의 대항마는 오픈소스 진영의 ROCm입니다. 오랫동안 “성능은 있는데 소프트웨어가 발목을 잡는다”는 평가를 받아왔습니다.
2026년, ROCm은 어디까지 왔나
그런데 2026년 현재 분위기가 달라졌습니다. ROCm 7.0은 이전 버전(6.0) 대비 추론 성능을 최대 3.5배 끌어올렸습니다.
핵심 프레임워크 지원도 사실상 동등 수준에 도달했습니다.
- PyTorch: ROCm을 1급(first-class) 옵션으로 공식 지원
- vLLM·llama.cpp: 추론 엔진 호환성 거의 동등
- JAX·Triton: 풀 지원 및 AMD GPU용 최적화 코드 생성
실제 성적표도 있습니다. 2026년 4월 1일 공개된 MLPerf Inference 6.0에서 MI355X는 서버 추론 워크로드 기준 B200과 한 자릿수 퍼센트 차이까지 따라붙었습니다.
아직 남은 격차
그래도 모든 영역이 동등해진 건 아닙니다. TensorRT-LLM, FlashAttention 3, NVIDIA NIM 컨테이너처럼 엔비디아 전용으로 최적화된 파이프라인에서는 여전히 CUDA가 우위입니다.
특히 메모리 바운드 워크로드의 어텐션 커널 최적화가 ROCm의 마지막 숙제로 꼽힙니다.
결론: 표준 추론은 ROCm으로 충분, 커스텀 커널 영역은 아직 CUDA의 땅.
그럼에도 의미 있는 신호가 있습니다. 메타가 6기가와트 규모의 ROCm 프로덕션 배치를 계획하고 있다는 점입니다. 빅테크가 이 정도 규모로 베팅한다는 건, ROCm이 ‘실험’을 넘어 ‘운영 가능’ 단계에 들어섰다는 방증입니다.
실전 관점
스타트업이나 개발팀이라면 “우리 워크로드가 표준 추론인가, 커스텀 커널인가”를 먼저 따져보세요. 표준 vLLM/PyTorch 추론이라면 AMD의 메모리·가격 이점이 크고, CUDA 전용 최적화에 묶여 있다면 전환비용이 만만치 않습니다.
2026 AI 반도체 로드맵 — 루빈 vs MI400
지금까지가 ‘현재’라면, 투자자가 진짜 봐야 할 건 ‘다음 세대’입니다. 2026년 하반기, 두 회사가 처음으로 동일한 시간대에 차세대 칩을 내놓습니다.
엔비디아는 루빈(Vera Rubin), AMD는 MI400 시리즈(MI450/MI455X)입니다. 2026년 AI 반도체 칩 로드맵 비교의 핵심이죠.
HBM4 시대의 개막
두 칩 모두 차세대 메모리 HBM4를 채택합니다. 이 지점에서 HBM 공급망이 다시 주목받는데, 메모리 수혜 구도가 궁금하다면 HBM4 관련주를 정리한 글을 함께 보면 흐름이 잡힙니다.
엔비디아 루빈은 288GB HBM4에 FP4 50 PFLOPS를 제공합니다. B200(10 PFLOPS)의 무려 5배입니다.
AMD MI455X는 메모리에서 다시 한 번 압도합니다. 432GB HBM4로 루빈(288GB)의 1.5배입니다.
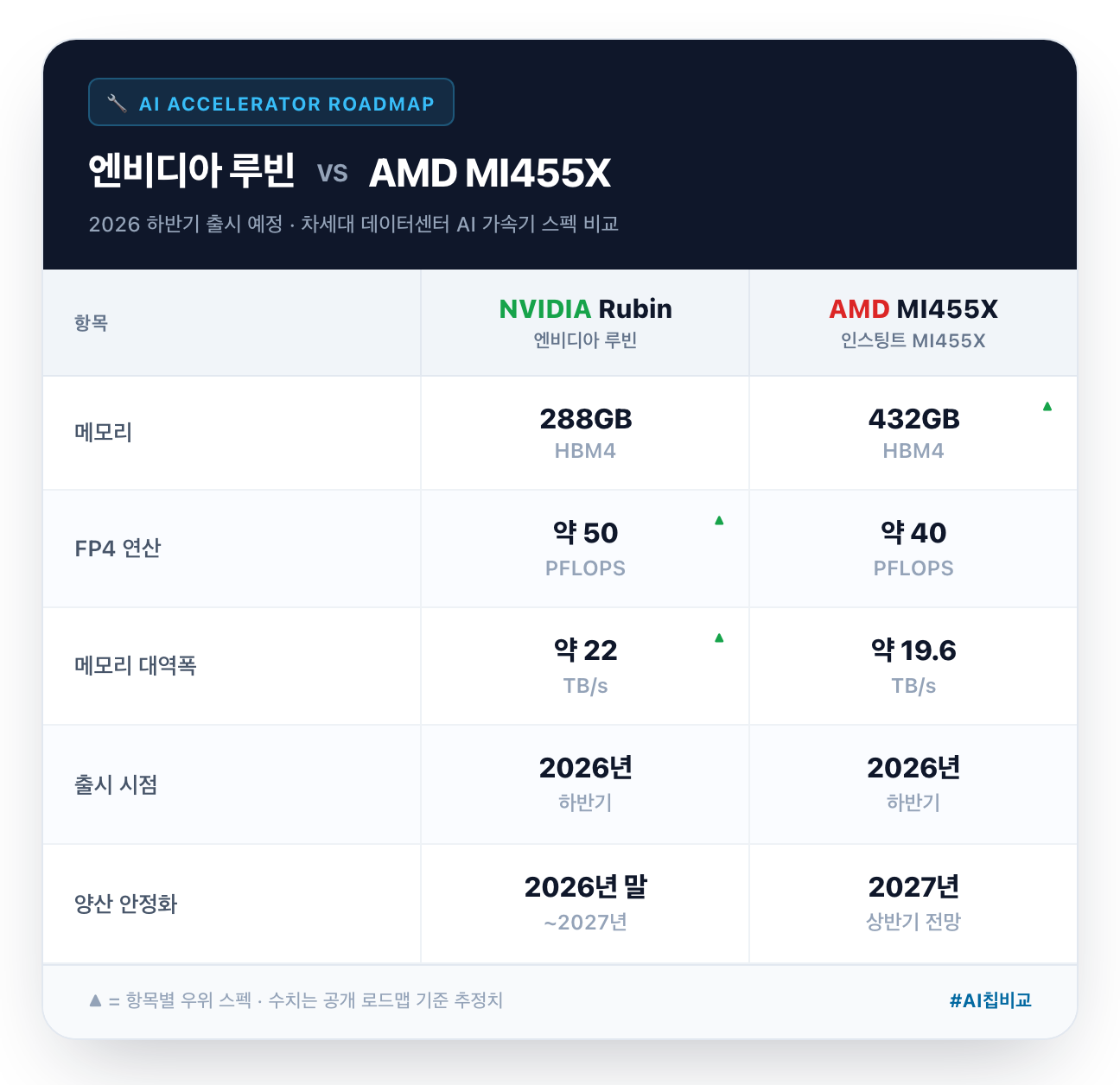
정리하면 루빈은 칩당 연산력(50 vs 40 PFLOPS)과 대역폭에서 앞서고, MI455X는 메모리 용량(432 vs 288GB)에서 앞섭니다. 현행 세대의 구도가 그대로 이어지는 셈입니다.
로드맵 슬라이드의 함정
여기서 투자자가 꼭 알아야 할 게 있습니다. ‘2026년 하반기 출시’와 ‘클라우드에서 빌려 쓸 수 있음’은 다릅니다.
엔지니어링 샘플과 소량 생산은 로드맵 시점에 맞춰 나오지만, 대량 양산은 종종 몇 개월에서 1년까지 밀립니다.
실제로 일부 보도는 AMD MI400의 대량 양산이 2027년 2분기로 늦춰질 수 있다고 봅니다. 엔비디아 루빈도 풀 양산은 들어갔지만 파트너사 공급은 하반기부터입니다.
로드맵 날짜는 ‘발표 시점’일 뿐, ‘실사용 시점’이 아니다.
그래서 2026년은 ‘교체’가 아니라 ‘병행’의 해에 가깝습니다. 많은 대형 고객이 엔비디아와 AMD를 섞은 혼합 클러스터로 리스크를 분산하는 전략을 택하고 있습니다.
투자 관점: 엔비디아 vs AMD, 어디에 베팅할까
마지막으로 가장 많이 궁금해하실 AI칩 투자 관점 엔비디아 vs AMD 비교입니다. 칩 스펙과 주식 투자 매력은 별개라는 점부터 짚고 가겠습니다.
실적: 규모는 엔비디아, 성장률은 AMD
먼저 최신 실적입니다. 엔비디아는 2027 회계연도 1분기(2026년 4월 26일 종료) 기준 매출 816억 달러, 데이터센터 매출만 752억 달러를 기록했습니다. 전년 대비 각각 85%, 92% 증가입니다.
총마진은 약 75%. 규모와 수익성 모두 압도적입니다.
AMD는 체급이 다릅니다. 2026년 1분기 데이터센터 매출은 사상 최대 58억 달러로 전년 대비 57% 늘었습니다.
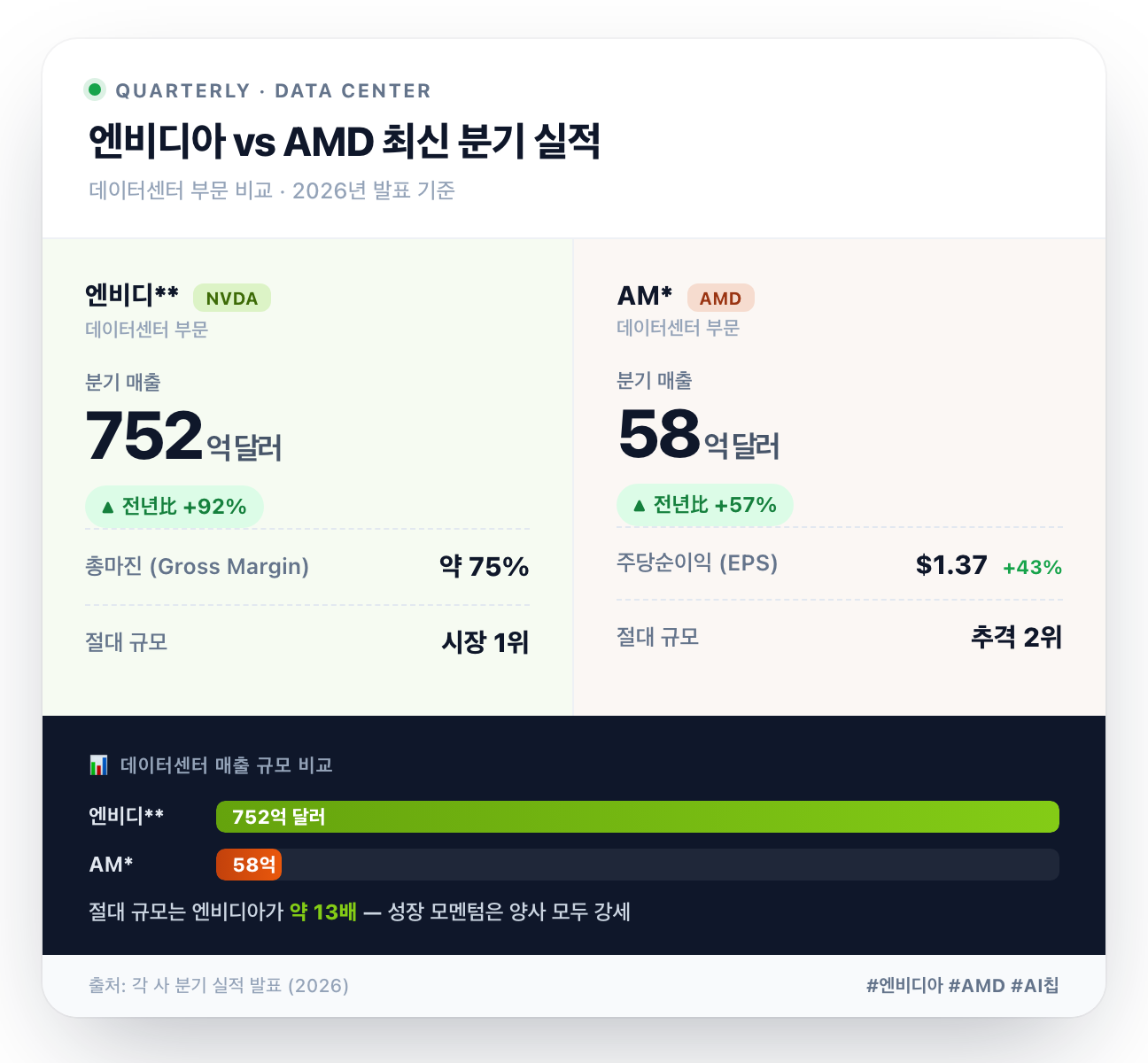
숫자에서 드러나듯 엔비디아의 데이터센터 매출은 AMD의 13배 수준입니다. 이게 시장 점유율 80~90% 대 5~7%라는 격차의 실체입니다.
주가: 2026년엔 AMD가 더 뛰었다
흥미로운 반전이 있습니다. 2026년 들어 주가 상승률은 AMD가 엔비디아를 앞섰습니다.
엔비디아는 2026년 들어 약 13% 상승에 그친 반면, AMD는 같은 기간 세 자릿수 급등을 보였습니다. 2026년 6월 초 기준 AMD 주가는 약 421달러, 52주 범위는 107~469달러입니다.
이유는 ‘기대치’에 있습니다. 엔비디아의 성장은 이미 주가에 많이 반영돼 있지만, AMD는 점유율을 조금만 빼앗아 와도 실적이 크게 점프하는 구조입니다.
판을 흔드는 빅테크 계약
AMD 재평가의 진짜 연료는 대형 계약입니다. 2025년 10월 OpenAI는 AMD와 6기가와트 규모의 GPU 공급 계약을 발표했습니다.
MI450을 2026년 하반기 1GW 배치부터 시작하며, 누적 하드웨어 매출 잠재력은 약 900억 달러로 추산됩니다. AMD는 OpenAI에 최대 1억 6천만 주의 신주인수권(워런트)까지 부여했습니다.
- OpenAI–AMD: 6GW, MI450 2026년 하반기 시작, 약 900억 달러 잠재 매출
- 오라클–AMD: MI450 5만 장을 2026년 3분기부터 OCI에 배치
- OpenAI–엔비디아: 최대 1,000억 달러 투자, 10GW 규모, 베라 루빈 기반
핵심은 OpenAI 같은 최대 고객조차 멀티벤더 전략으로 돌아섰다는 점입니다. 한 회사에 100% 의존하던 시대가 끝나가고 있다는 신호죠.
상황별 선택 기준
그래서 어디에 베팅하느냐? 정답은 투자 성향에 따라 갈립니다.
안정·해자를 본다면 엔비디아. CUDA 생태계, 75% 마진, 10GW급 계약까지 ‘이기는 말’의 조건을 다 갖췄습니다. 다만 높은 밸류에이션이 부담입니다.
업사이드·재평가를 본다면 AMD. 점유율이 한 자릿수라 빼앗아 올 시장이 넓고, 빅테크 계약이 현실화되면 실적 레버리지가 큽니다. 대신 양산 지연·소프트웨어 격차라는 리스크를 감수해야 합니다.
개인적으로는 둘 중 하나를 고르기보다, AI 인프라 전반에 분산하는 접근이 마음 편했습니다. 두 회사가 동시에 성장하는 국면에서는 ‘AMD냐 엔비디아냐’보다 ‘AI 반도체 사이클 전체’를 보는 시각이 유효합니다. 이 큰 그림이 궁금하다면 AI 반도체 관련주를 정리한 가이드가 출발점이 됩니다.
자주 묻는 질문
Q. 결국 엔비디아와 AMD AI칩 중 성능이 더 좋은 건 누구인가요?
스펙시트만 보면 AMD MI355X가 메모리(288GB)와 FP4 연산(20 PFLOPS)에서 앞섭니다. 하지만 실제 워크로드에서는 엔비디아의 소프트웨어(CUDA)와 클러스터 효율이 격차를 메웁니다. ‘칩 한 장’은 AMD, ‘시스템 전체’는 엔비디아가 우세하다고 보는 게 정확합니다.
Q. AMD가 엔비디아를 따라잡을 수 있을까요?
‘추월’보다는 ‘점유율 잠식’이 현실적 시나리오입니다. 엔비디아 80~90% 독점 구도에서 AMD가 두 자릿수 점유율만 확보해도 매출이 크게 늘어납니다. OpenAI·오라클·메타 계약이 그 가능성을 뒷받침하지만, 양산 일정과 ROCm 성숙도가 관건입니다.
Q. AI 가속기 투자, 엔비디아와 AMD 중 무엇을 사야 하나요?
안정성과 압도적 해자를 원하면 엔비디아, 점유율 확대에 따른 재평가 업사이드를 노린다면 AMD가 유효합니다. 2026년 들어선 AMD 주가 상승률이 더 컸지만, 이는 변동성도 그만큼 크다는 의미입니다. 본 글은 정보 제공이며 투자 권유가 아닙니다.
Q. 루빈과 MI400은 언제부터 실제로 쓸 수 있나요?
둘 다 2026년 하반기 출시가 목표지만, 클라우드에서 안정적으로 빌려 쓰는 시점은 그보다 3~6개월 이상 늦습니다. 특히 AMD MI400의 대량 양산은 2027년 상반기로 밀릴 수 있다는 전망이 있어, 로드맵 날짜를 그대로 믿기보다 양산·공급 뉴스를 따로 확인해야 합니다.
Q. CUDA에 묶이지 않고 AMD로 갈아탈 수 있나요?
표준 PyTorch·vLLM 기반 추론이라면 ROCm 7.0으로 충분히 전환 가능합니다. 다만 TensorRT-LLM이나 FlashAttention 같은 엔비디아 전용 커널에 의존하는 파이프라인은 전환비용이 큽니다. 워크로드 성격을 먼저 점검하는 게 우선입니다.